
SQL Server hierarchyid: A Built-In Alternative to Recursive CTEs
In the previous post, we walked through recursive CTEs and how their three parts (anchor, recursive member, outer query) work together to traverse a hierarchy. Recursive CTEs are flexible and require no special schema design, but they re-walk the tree every time you query it.
SQL Server offers a different approach: the hierarchyid data type. Instead of discovering the tree structure at query time, you encode each node’s position directly in the data. The tree structure is baked into the column values themselves.
What Is hierarchyid?
hierarchyid is a system CLR data type that stores a node’s position in a tree as a compact binary value. Each value represents a path from the root to a specific node.
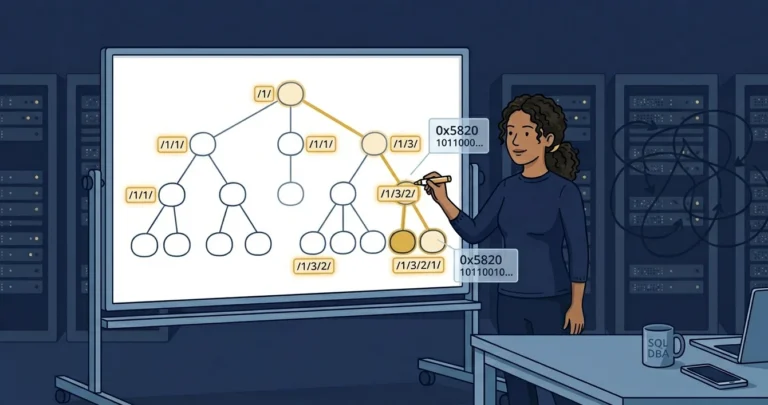
When you call ToString() on a hierarchyid value, you see a human-readable path like /1/3/2/. That means: root, first child, third grandchild, second great-grandchild. The binary representation is more compact, but the slash notation makes it easy to reason about.
The key insight: because the position is encoded in the value, you can answer hierarchy questions (Is A an ancestor of B? What level is this node?) without any joins at all.
Setting Up a Hierarchy Table
Let us build the same org chart from the recursive CTEs post, this time using hierarchyid:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE TABLE #employees ( [node] hierarchyid NOT NULL PRIMARY KEY , [employee_id] int NOT NULL , [employee_name] varchar(50) NOT NULL , [depth] AS [node].GetLevel() PERSISTED ); CREATE UNIQUE INDEX [UX_employee_id] ON #employees ([employee_id]); INSERT INTO #employees ([node], [employee_id], [employee_name]) VALUES ('/', 1, 'Dana') , ('/1/', 2, 'Marcus') , ('/2/', 3, 'Priya') , ('/1/1/', 4, 'Tomoko') , ('/1/2/', 5, 'Aisha') , ('/2/1/', 6, 'Lin'); |
A few things to notice:
The path encodes the structure. Dana is / (the root). Marcus is /1/ (first child of root). Tomoko is /1/1/ (first child of Marcus). You can read the reporting chain directly from the value.
The depth column is computed. GetLevel() returns the node’s depth in the tree. By marking it PERSISTED, SQL Server stores it physically, so depth queries do not need to call the method at runtime.
No manager_id column. The parent-child relationship is implicit in the hierarchyid value. If you need the parent node, call [node].GetAncestor(1).
The Essential Methods
hierarchyid provides a small set of methods that replace most recursive CTE patterns:
GetLevel()
Returns the depth of the node. The root is level 0.
|
1 2 3 4 5 6 7 8 |
SELECT [e].[employee_name] , [e].[node].ToString() AS [path] , [e].[node].GetLevel() AS [depth] FROM #employees AS [e] ORDER BY [e].[node]; |
GetAncestor(n)
Returns the node that is n levels up. GetAncestor(1) gives the direct parent.
|
1 2 3 4 5 6 7 8 9 10 |
/* Find each employee's direct manager */ SELECT [e].[employee_name] , [mgr].[employee_name] AS [manager_name] FROM #employees AS [e] LEFT JOIN #employees AS [mgr] ON [e].[node].GetAncestor(1) = [mgr].[node] ORDER BY [e].[node]; |
This is one join, not a recursive CTE. For a table with a million rows, that matters.
IsDescendantOf()
Returns 1 if the node is a descendant of (or equal to) the specified ancestor. This is the method that replaces the most common recursive CTE use case: “give me everyone under this person.”
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
/* Find everyone who reports to Marcus, at any depth */ DECLARE @marcus hierarchyid; SELECT @marcus = [e].[node] FROM #employees AS [e] WHERE [e].[employee_id] = 2; SELECT [e].[employee_name] , [e].[node].ToString() AS [path] , [e].[depth] FROM #employees AS [e] WHERE [e].[node].IsDescendantOf(@marcus) = 1 AND [e].[node] <> @marcus ORDER BY [e].[node]; |
No recursion. No anchor and recursive member. Just a WHERE clause.
GetDescendant()
Generates a new hierarchyid value for inserting a child node. This is how you add new nodes without recalculating the entire tree.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
/* Add a new direct report under Priya, after Lin */ DECLARE @priya hierarchyid; DECLARE @lastChild hierarchyid; SELECT @priya = [e].[node] FROM #employees AS [e] WHERE [e].[employee_id] = 3; /* Find Priya's current last child */ SELECT @lastChild = MAX([e].[node]) FROM #employees AS [e] WHERE [e].[node].GetAncestor(1) = @priya; /* Insert after the last child */ INSERT INTO #employees ([node], [employee_id], [employee_name]) VALUES (@priya.GetDescendant(@lastChild, NULL), 7, 'Ravi'); |
GetDescendant takes two parameters: the child to insert after and the child to insert before. Passing NULL as the second parameter means “insert at the end.”
Indexing Strategies
How you index a hierarchyid column determines which queries are fast.
Depth-first index (primary key on the hierarchyid column): Rows are stored in tree-walking order. Subtree queries (IsDescendantOf) are range scans because all descendants share a common prefix. This is the most common choice.
Breadth-first index (composite index on depth + hierarchyid): Rows at the same level are stored together. Useful when you frequently query “all employees at level 3” or “all peers of this node.”
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/* Breadth-first index for level-based queries */ CREATE INDEX [IX_breadth] ON #employees ([depth], [node]); /* All employees at depth 2 */ SELECT [e].[employee_name] , [e].[node].ToString() AS [path] FROM #employees AS [e] WHERE [e].[depth] = 2 ORDER BY [e].[node]; |
You can have both indexes on the same table. The optimizer picks the one that fits the query.
Moving a Subtree
One operation that is painful with recursive CTEs is moving a node (and all its descendants) to a new parent. With hierarchyid, you use GetReparentedValue():
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
/* Move Marcus (and his subtree) to report to Priya instead of Dana */ DECLARE @marcus hierarchyid; DECLARE @oldParent hierarchyid; DECLARE @newParent hierarchyid; SELECT @marcus = [e].[node] FROM #employees AS [e] WHERE [e].[employee_id] = 2; SET @oldParent = @marcus.GetAncestor(1); SELECT @newParent = [e].[node] FROM #employees AS [e] WHERE [e].[employee_id] = 3; UPDATE [e] SET [e].[node] = [e].[node].GetReparentedValue(@oldParent, @newParent) FROM #employees AS [e] WHERE [e].[node].IsDescendantOf(@marcus) = 1; |
This single UPDATE moves Marcus, Tomoko, and Aisha under Priya. Their hierarchyid values are recalculated to reflect the new position. With a recursive CTE approach, you would need to update parent pointers and re-walk the tree to verify the new structure.
When to Use hierarchyid vs. Recursive CTEs
Neither approach is universally better. The right choice depends on your situation:
| Consideration | Recursive CTE | hierarchyid |
|---|---|---|
| Schema changes required | None; works with any parent-child table | Requires a hierarchyid column and possibly restructuring inserts |
| Ad-hoc queries on existing data | Excellent; no schema changes needed | Requires migrating data first |
| Subtree query performance | Re-walks the tree each time (nested loops) | Single range scan on the index |
| Depth/level queries | Requires the CTE to compute depth | Computed column with index support |
| Moving subtrees | Difficult; update parent pointers and re-verify | Single UPDATE with GetReparentedValue() |
| Inserting new nodes | Simple INSERT with parent_id | Requires GetDescendant() call to generate the new path |
| Readability | Familiar SQL; self-documenting | Methods like GetReparentedValue() have a learning curve |
Use recursive CTEs when you are writing ad-hoc queries against existing parent-child tables, when the hierarchy is small, or when you cannot change the schema.
Use hierarchyid when you own the schema, query the hierarchy frequently, and performance matters. The upfront cost of restructuring pays off in faster reads and simpler subtree operations.
Wrapping Up
The hierarchyid data type encodes tree position directly into the data, turning recursive walks into index lookups. It requires more thought at design time (generating paths with GetDescendant, choosing depth-first vs. breadth-first indexing), but it pays that cost back every time you query the hierarchy.
Combined with the recursive CTE fundamentals from the previous post, you now have two solid tools for hierarchical data in SQL Server. Pick the one that fits your constraints.
If you are using hierarchyid in production, I would like to hear how it is working for you. You can find me on Bluesky and LinkedIn.